
Parquet file format – Describe core data concept
Parquet file format
Parquet is a columnar storage file format designed for efficient data processing and analytics in big data environments. It provides a highly optimized and compressed representation of structured data, making it well-suited for handling large datasets. Parquet files organize data by columns rather than rows and therefore support advanced column pruning and predicate push-down optimizations.
Figure 1-6 shows a Parquet file that stores sales data for an e-commerce business. Instead of storing all the attributes of a sale in row-based format, Parquet stores each column of data separately. This columnar organization allows for efficient compression and encoding techniques specific to each column, reducing storage requirements and improving query performance. The example shown contains these columns: OrderID, CustomerID, ProductID, Quantity, Price, and Timestamp.

FIGURE 1-6 The Parquet file format
Parquet files offer several advantages. The columnar storage format reduces disk I/O and improves query performance, especially when queries involve only a subset of columns. Parquet leverages advanced compression techniques, such as run-length encoding (RLE) and dictionary encoding, to further reduce the storage footprint while maintaining data integrity. The format also supports nested and complex data types and therefore can represent hierar-chical structures.
Parquet is widely adopted in big data processing frameworks such as Apache Hadoop and Apache Spark, as it accelerates analytics workloads by efficiently reading and processing only the required columns. Its compatibility with various data processing tools makes it a preferred choice for high-performance data analytics and data warehousing scenarios.
10 CHAPTER 1 Describe core data concept
Avro file format
When it comes to storing and exchanging structured data efficiently, the Avro file format stands out as a compact and dynamic solution. Embracing a binary encoding approach, Avro files offer high-performance data processing and storage capabilities. What sets Avro apart is its ability to provide a self-describing schema alongside the data, facilitating schema evolution and dynamic typing.
Figure 1-7 shows an example of the Avro schema defining the structure of the user pro-file data. The type field specifies that it is a record, the name is User Profile, and the fields are defined in the fields array. In this case, the fields include the user’s name (string), age (int), location (string), and interests (an array of strings).
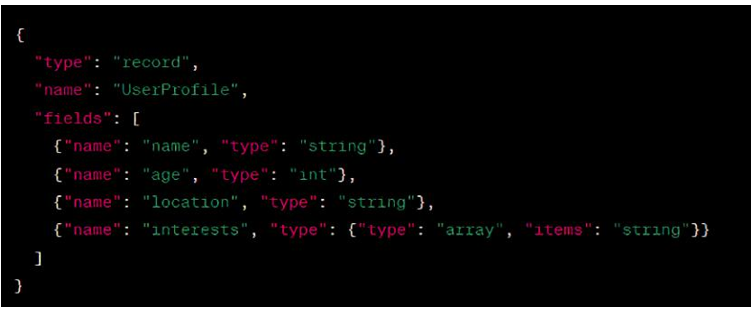
FIGURE 1-7 The Avro file format
Within this file, both the data and its accompanying schema are encapsulated. This inclu-sion empowers flexibility, allowing the schema to evolve over time without compromising compatibility with existing data. The schema is a rich and diverse representation of structured information.
Avro files offer remarkable advantages. Through their binary encoding, these files achieve exceptional compactness and efficiency, making them ideal for managing and transmitting large volumes of data. The self-describing nature of Avro allows seamless schema evolution, facilitating the adaptation to changing data requirements. Additionally, Avro supports complex data structures, including nested and hierarchical relationships, and therefore can represent intricate information models.
With its outstanding performance, flexibility, and schema evolution capabilities, the Avro file format has garnered widespread adoption within big data processing frameworks such as Apache Hadoop and Apache Spark. Its ability to efficiently handle high-volume data
Skill 1.2: Identify options for data storage CHAPTER 1 11
processing, analytics, and seamless interoperability between systems positions Avro as a powerful and dynamic choice.